
I am an Assistant Professor at Leiden University in the Leiden Institute for Advanced Computer Science (LIACS). Previously I was a postdoctoral researcher at the University of Amsterdam, working with with Prof. Cees Snoek. I completed my PhD at the University of Bristol, advised by Prof. Dima Damen and Prof. Walterio Mayol-Cuevas. My research spans video understanding, fine-grained recognition, and learning from limited labels. I am particularly interested in their intersections, studying how detailed temporal and semantic structure can be learned from sparse or imperfect supervision.
Contact: h.r.doughty *at* liacs.leidenuniv.nl
News & Activities
- June: I'm hiring a postdoc, please reach out if you're interested
-
January: I have a PhD vacancy on fine-grained visual understanding - January: Our paper "Let's Split Up: Zero-Shot Classifier Edits for Fine-Grained Video Understanding" was accepted to ICLR 2026. Details coming soon.
- December: I'll be giving a talk at the Joint Egocentric Vision Workshop @ CVPR 2026
- November: I became an associate editor for TPAMI
- June: I gave a talk at the AC workshop at CVPR 2025
- May: Our High Tech Systems and Materials project 'DUAL-IMPACT' was funded
- February: HD-EPIC was accepted to CVPR 2025
- February: I gave a talk at the HAVA lab in the University of Amsterdam
- January: I'll be giving a keynote at the CVPR 2025 workshop on Interactive Video Search and Exploration (IViSE)
- October: Welcome to Luc Sträter who started his PhD at LIACS
- September: Two papers accepted to ACCV as orals. Details coming soon.
- September: I'll be serving as area chair for CVPR 2025, ICCV 2025 and NeurIPS 2025
- July 2024: I gave a talk at the African Summer School on Computer Vision
- July 2024: Our paper SelEx: Self-Expertise in Fine-Grained Generalized Category Discovery is accepted to ECCV 2024, more details coming soon.
- May 2024: I have a PhD vacancy on 'Detailed Video Understanding'
- April 2024: I gave a talk in the Visipedia workshop at the University of Copenhagen
- April 2024: Welcome to Kaiting Liu who started her PhD at LIACS
- March 2024: I gave a talk at the University of Bath
- February 2024: Our paper Low-Resource Vision Challenges for Foundational Models is accepted to CVPR 2024
- February 2024: I'm co-organizing the CVPR 2024 workshop on What is Next in Video Understanding?
- January 2024: I am organizing NCCV 2024
- December 2023: Congratulations to Dr. Fida Mohammad Thoker who successfully defended his thesis titled Video-Efficient Foundation Models
- Novemeber 2023: Happy to be a top reviewer for NeurIPS 2023.
- October 2023: I'm hiring for two PhD positions in 'Detailed Video Understanding'
- September 2023: Two papers accepted to NeurIPS
- September 2023: I joined Leiden University as an Assistant Professor
- August 2023: I'm thrilled to receive a Veni grant for my project "From What to How: Perceiving Subtle Details in Videos"
- July 2023: Our paper "Tubelet-Contrastive Self-Supervision for Video-Efficient Generalization" was accepted to ICCV, pre-print available here
- July 2023: In September I'll join Leiden University as an Assistant Professor, look out for PhD openings!
- June 2023: I gave a talk at the CVPR 2023 workshop on Learning with Limited Labelled Data for Image and Video Understanding
- April 2023: I became an associate editor of CVIU
- February 2023: I gave a talk at the Rising Stars in AI Symposium 2023 in KAUST
- December 2022: Excited to be a Workshop Chair for BMVC 2023
- December 2022: I'm honored to serve as an Area Chair for ICCV 2023
- December 2022: I gave a guest lecture at the University of Catania
- October 2022: Happy to be an outstanding reviewer for ECCV 2022
- September 2022: I became an ELLIS member
- September 2022: I gave a talk at the 2022 Video Understanding Symposium
- July 2022: 'How Severe is Benchmark-Sensitivity in Video Self-Supervised Learning?' is accepted to ECCV
- June 2022: I was a panelist at Women in Computer Vision CVPR 2022
- May 2022: I gave a talk at the Computer Vision by Learning Summer School
- March 2022: Our papers on Pseudo Adverbs and Audio-Adaptive Action Recognition are accepted to CVPR.
- September 2021: Our paper Rescaling Egocentric Vision is accepted for publication in IJCV
- September 2021: I'm an Outstanding Reviewer for ICCV 2021
- August 2021: Our paper Skeleton-Contrastive 3D Action Representation Learning was accepted at ACM Multimedia 2021
- July 2021: I'm co-organizing the NeurIPS'21 Workshop on Pre-registration in ML
- May 2021: Happy to be an outstanding reviewer for CVPR 2021
- April 2021: I'm co-organizing the Workshop on Structured Representations for Video Understanding at ICCV.
- March 2021: Our paper On Semantic Similarity in Video Retrieval got accepted at CVPR 2021.
- February 2021: I gave a talk at the University of Toronto's AI in Robotics Seminar Series.
- October 2020: Successfully defended my PhD thesis "Skill Determination from Long Videos". Thank you to my examiners Josef Sivic and Bill Freeman.
- August 2020: Proud to be an Outstanding Reviewer for ECCV 2020
- July 2020: EPIC-Kitchens-100 released. This is an extension of the original EPIC-Kitchens, now up 100 hours of video and 90,000 action segments.
- June 2020: I presented our CVPR paper Action Modifers: Learning from Adverbs in Instructional Videos at the Video Pentathlon workshop.
- April 2020: The journal paper EPIC-KITCHENS Dataset: Collection Challenges and Baselines has been accepted to IEEE Transactions on Pattern Analysis and Machine Intelligence
- Feb 2020: Action Modifers: Learning from Adverbs in Instructional Videos is accepted in CVPR 2020.
- Jan 2020: I'm co-organizing the Women in Computer Vision and Egocentric Perception, Interaction and Computing workshops at CVPR 2020.
- Dec 2019: Our new paper on 'Action Modifiers' is available on arXiv
- June 2019: We're presenting our paper on rank-aware temporal attention for skill determination at CVPR 2019.
Publications
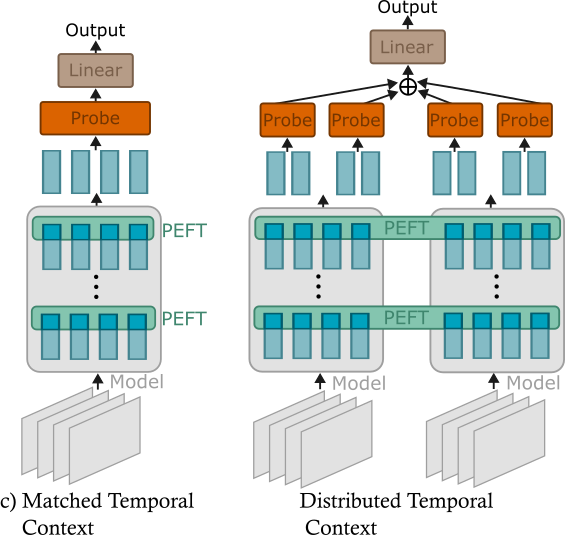 |
Where do We (Not) Need Temporal Context in Low-Resource Video Task Adaptation Luc Sträter, Hazel Doughty arXiv, 2026. [Webpage] [ArXiv] [Code Coming Soon] |
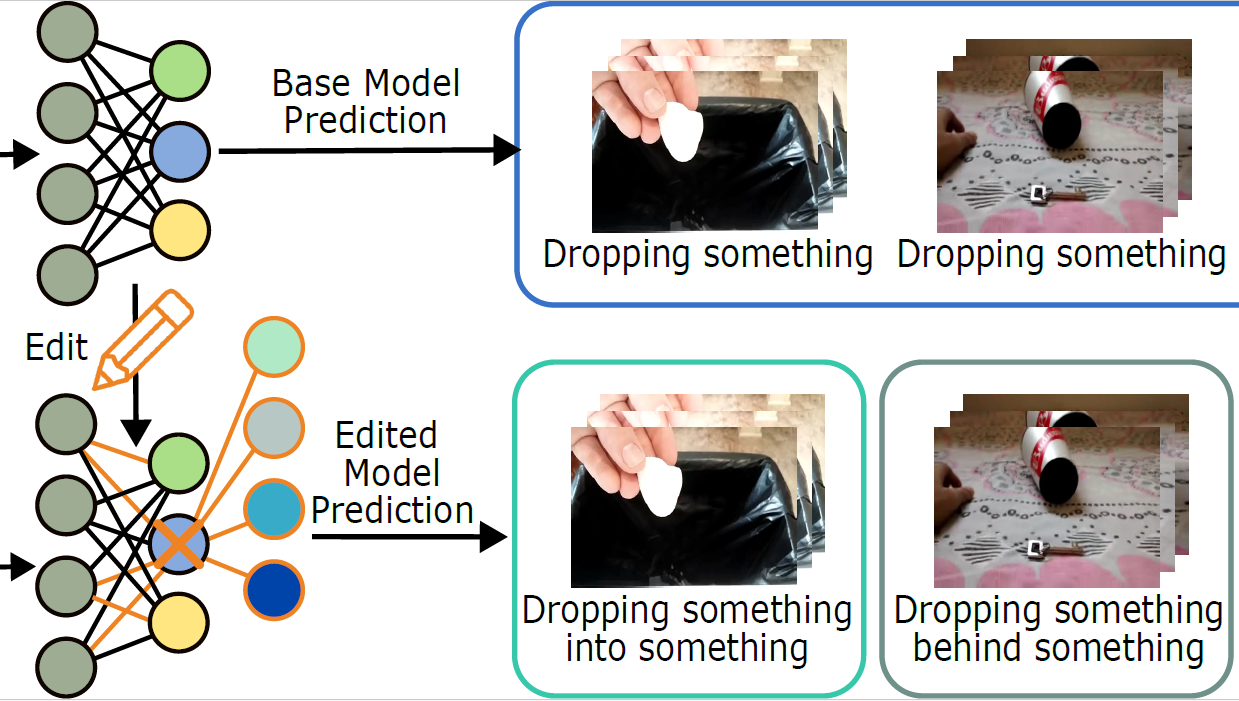 |
Let's Split Up: Zero-Shot Classifier Edits for Fine-Grained Video Understanding Kaiting Liu, Hazel Doughty International Conference on Learning Representations (ICLR), 2026. [Webpage] [ArXiv] [Code & Benchmarks] |
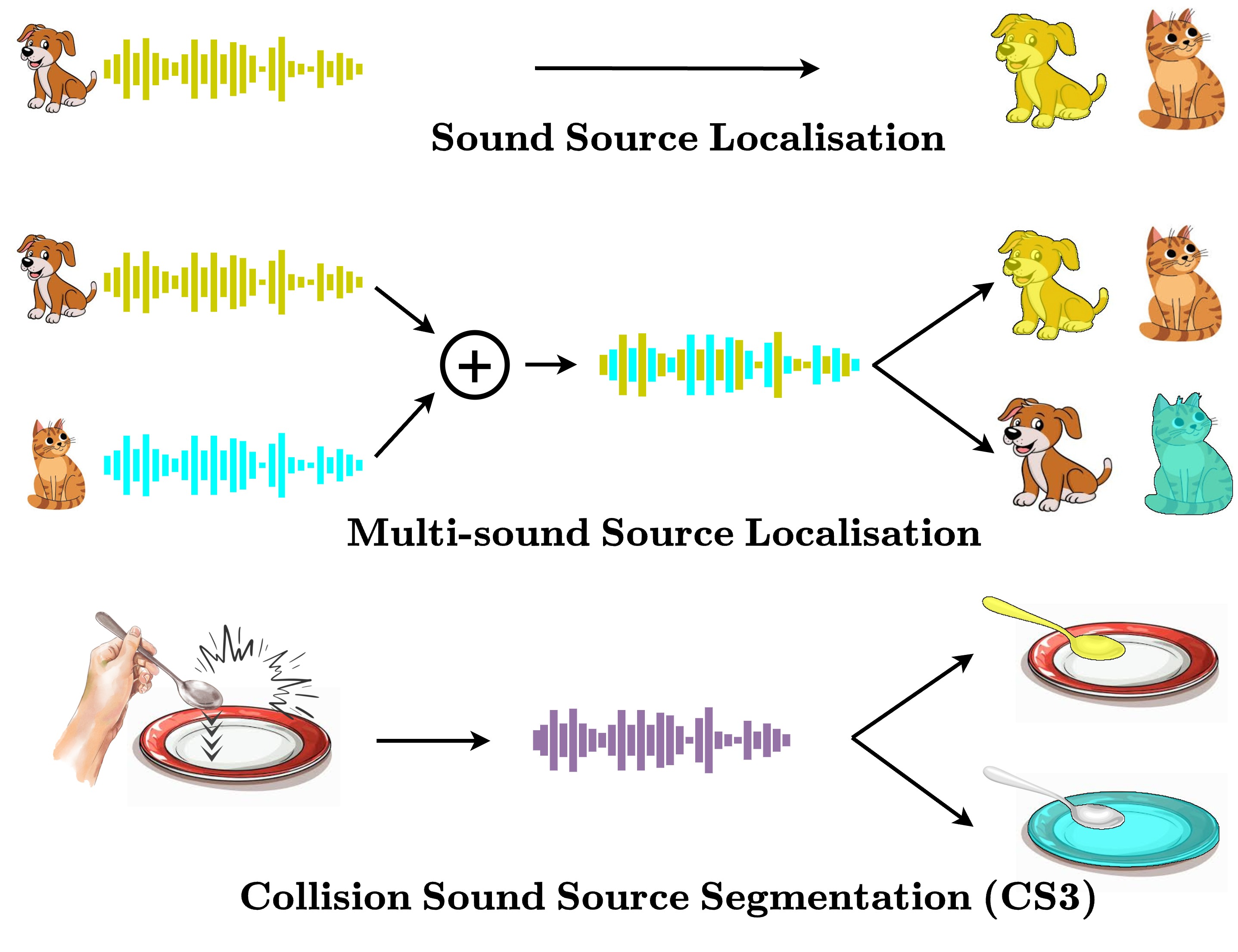 |
Segmenting Collision Sounds in Egocentric Video Kranti Kumar Parida, Omar Emara, Hazel Doughty, Dima Damen Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. [Webpage] [ArXiv] [Code & Data] |
 |
SEVERE++: Evaluating Benchmark Sensitivity in Generalization of Video Representation Learning Fida Mohammad Thoker, Letian Jiang, Chen Zhao, Piyush Bagad, Hazel Doughty, Bernard Ghanem, Cees Snoek ArXiv, 2025. [arXiv] |
 |
HD-EPIC: A Highly-Detailed Egocentric Video Dataset Toby Perrett, Ahmad Darkhalil, Saptarshi Sinha, Omar Emara, Sam Pollard, Kranti Parida, Kaiting Liu, Prajwal Gatti, Siddhant Bansal, Kevin Flanagan, Jacob Chalk, Zhifan Zhu, Rhodri Guerrier, Fahd Abdelazim, Bin Zhu, Davide Moltisanti, Michael Wray, Hazel Doughty, Dima Damen Conference on Computer Vision and Pattern Recognition (CVPR), 2025. [Webpage] [ArXiv] [Dataset] |
 |
LocoMotion: Learning Motion-Focused Video-Language Representations Hazel Doughty, Fida Mohammad Thoker, Cees Snoek Asian Conference on Computer Vision (ACCV), 2024. (Oral) [Webpage] [ArXiv] |
 |
Beyond Coarse-Grained Matching in Video-Text Retrieval Aozhu Chen, Hazel Doughty, Xirong Li, Cees Snoek Asian Conference on Computer Vision (ACCV), 2024. (Oral) [ArXiv] |
 |
SelEx: Self-Expertise In Fine-Grained Generalized Category Discovery Sarah Rastegar, Mohammadreza Salehi, Yuki Asano, Hazel Doughty, Cees Snoek European Conference on Computer Vision (ECCV), 2024. [arXiv] [Code] |
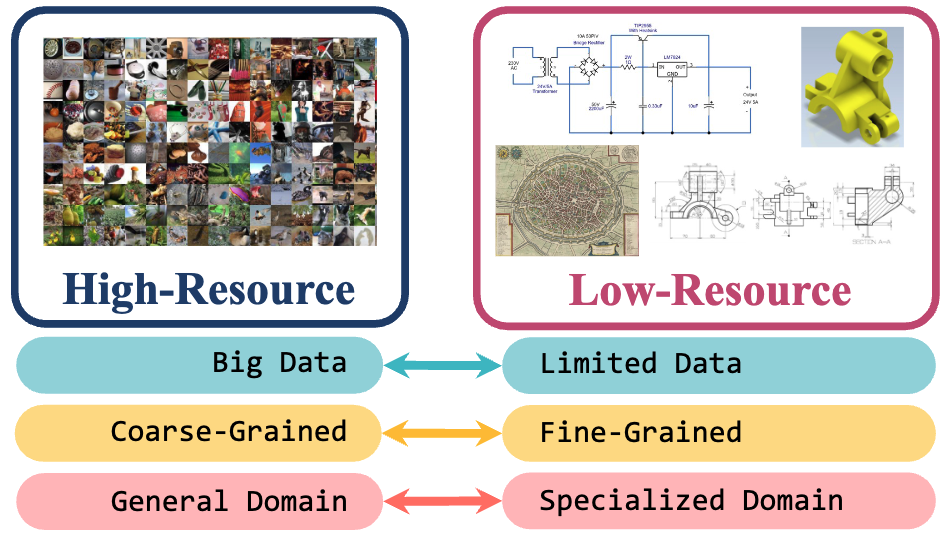 |
Low-Resource Vision Challenges for Foundation Models Yunhua Zhang, Hazel Doughty, Cees Snoek Conference on Computer Vision and Pattern Recognition (CVPR), 2024. [Webpage] [arXiv] |
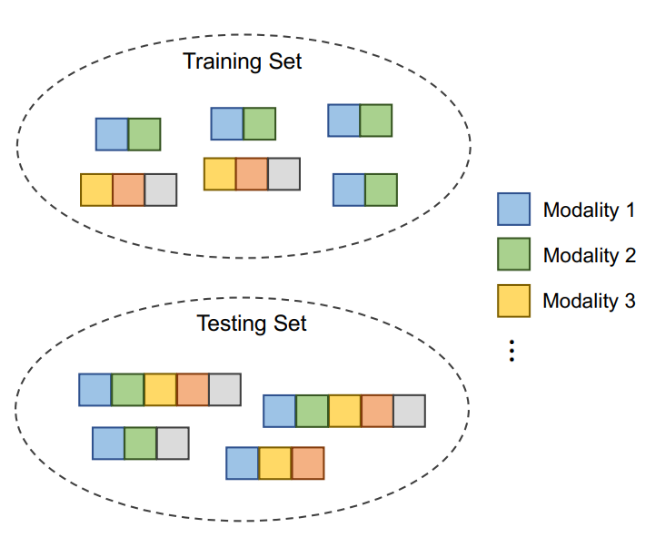 |
Learning Unseen Modality Interaction Yunhua Zhang, Hazel Doughty, Cees Snoek Advances in Neural Information Processing Systems (NeurIPS), 2023. [Webpage] [arXiv] [Code] |
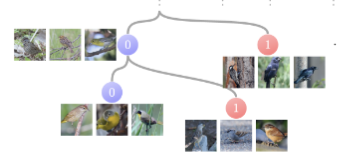 |
Learn to Categorize or Categorize to Learn? Self-Coding for Generalized Category Discovery Sarah Rastegar, Hazel Doughty, Cees Snoek Advances in Neural Information Processing Systems (NeurIPS), 2023. [arXiv] [Code] |
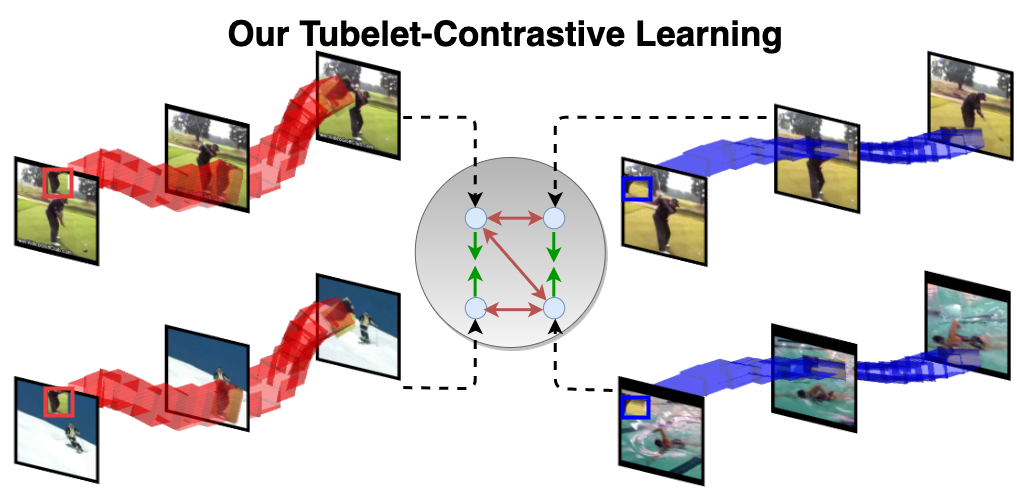 |
Tubelet-Contrastive Self-Supervision for Video-Efficient Generalization Fida Mohammad Thoker, Hazel Doughty, Cees Snoek International Conference on Computer Vision (ICCV), 2023. [Webpage] [arXiv] [Code] |
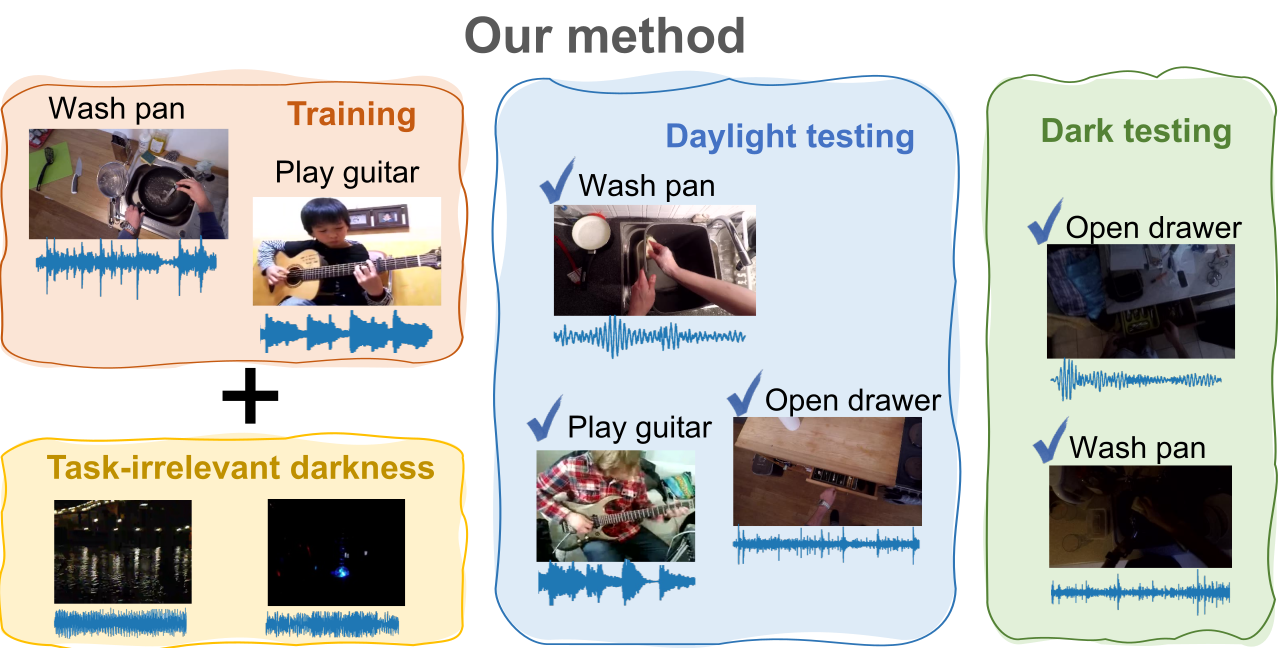 |
Day2Dark: Pseudo-Supervised Activity Recognition beyond Silent Daylight Yunhua Zhang, Hazel Doughty, Cees Snoek International Journal of Computer Vision (IJCV), 2025. [arXiv] |
| |
How Severe is Benchmark-Sensitivity in Video Self-Supervised Learning? Fida Mohammad Thoker, Hazel Doughty, Piyush Bagad, Cees Snoek European Conference on Computer Vision (ECCV), 2022. [Webpage] [arXiv] [Code] |
 |
How Do You Do It? Fine-Grained Action Understanding with Pseudo-Adverbs Hazel Doughty and Cees Snoek Conference on Computer Vision and Pattern Recognition (CVPR), 2022. [Webpage] [arXiv] [Dataset and Code] |
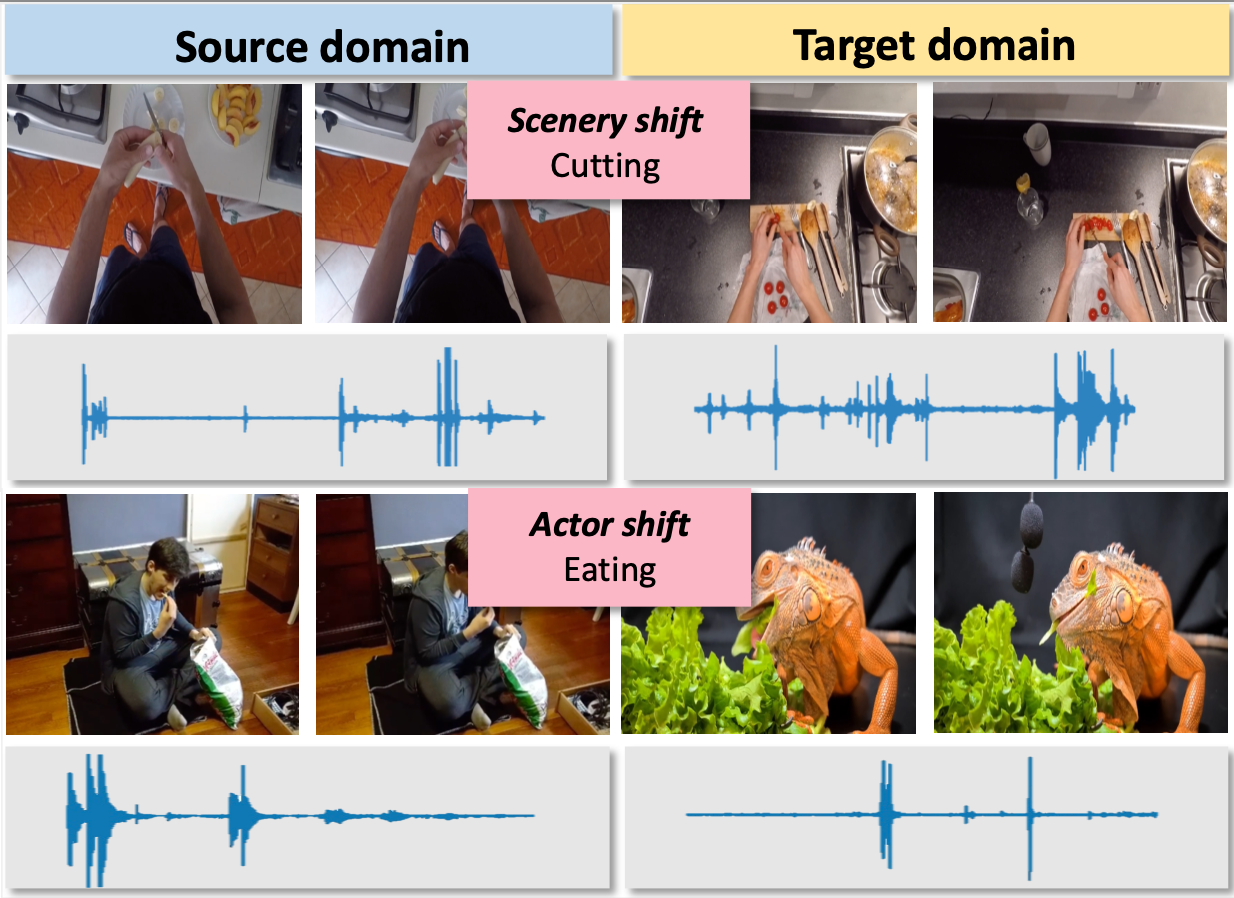 |
Audio-Adaptive Activity Recognition Across Video Domains Yunhua Zhang, Hazel Doughty, Ling Shao, Cees Snoek Conference on Computer Vision and Pattern Recognition (CVPR), 2022. [Webpage] [arXiv] [Code] |
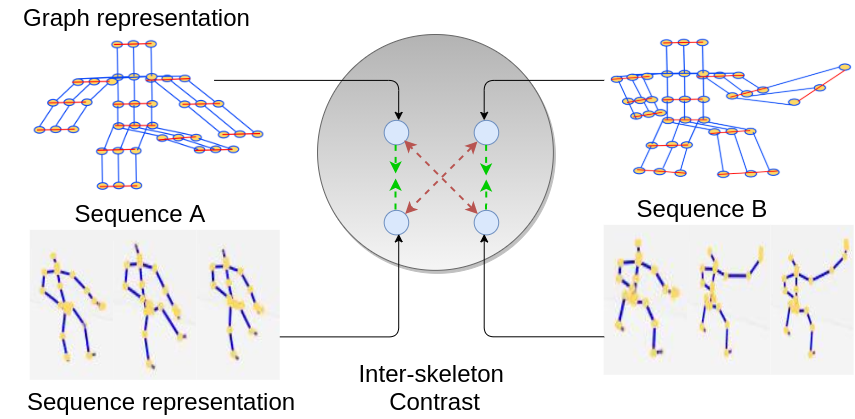 |
Skeleton-Contrastive 3D Action Representation Learning Fida Mohammad Thoker, Hazel Doughty, Cees Snoek ACM International Conference on Multimedia (ACMMM), 2021 [arXiv] [Code] |
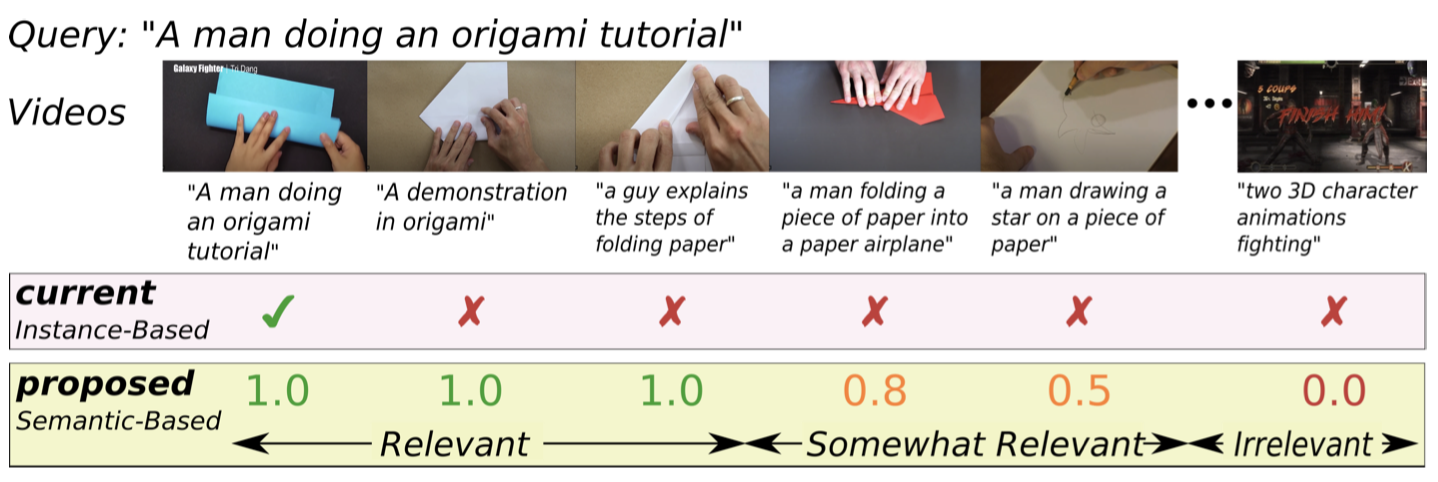 |
On Semantic Similarity in Video Retrieval Michael Wray, Hazel Doughty and Dima Damen Conference on Computer Vision and Pattern Recognition (CVPR), 2021. [Webpage] [arXiv] |
 |
Rescaling Egocentric Vision: EPIC-KITCHENS-100 Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Antonino Furnari, Evangelos Kazakos, Jian Ma, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, Michael Wray International Journal of Computer Vision (IJCV), 2021. [Webpage] [arXiv] [Dataset and Code] |
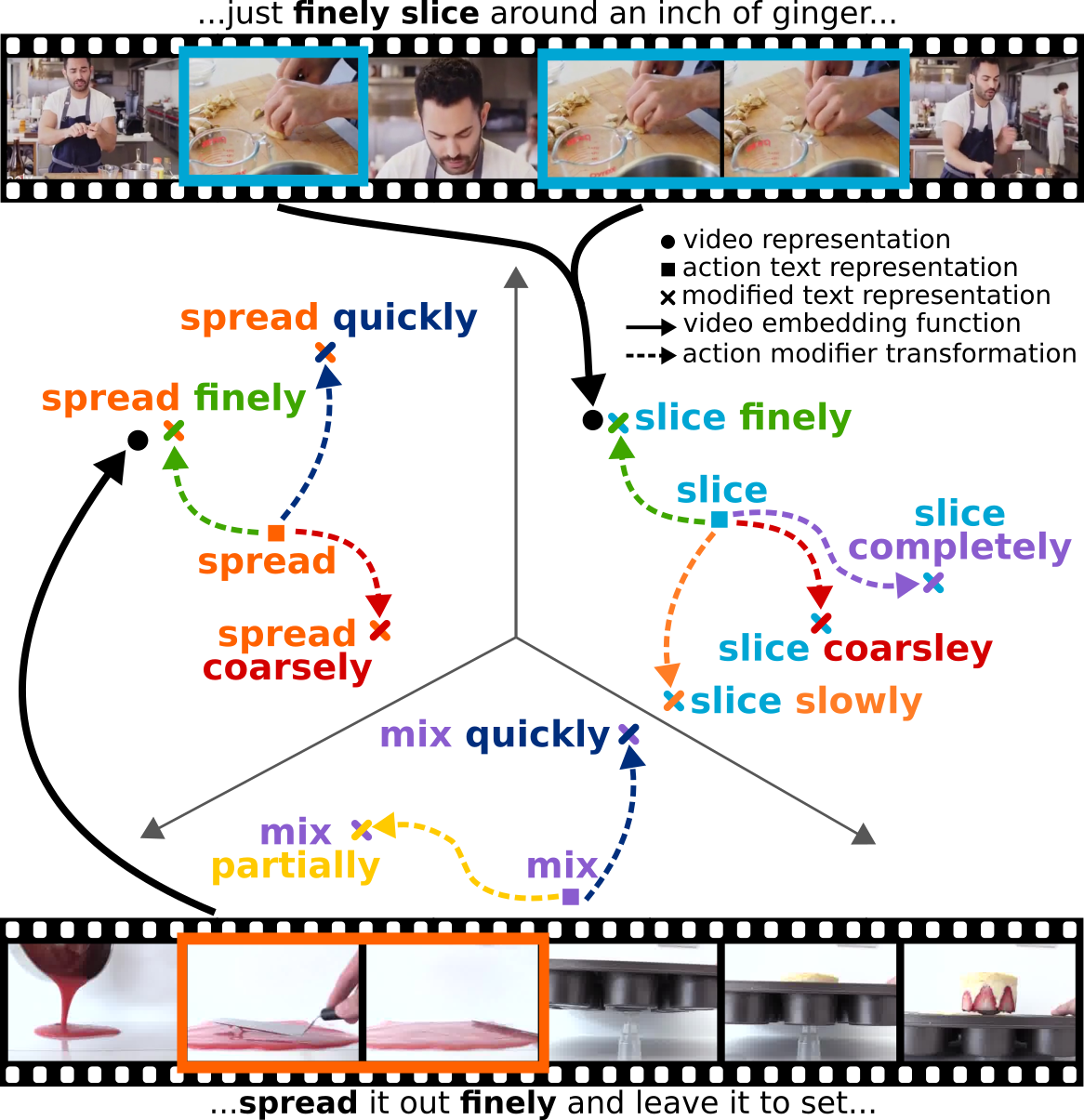 |
Action Modifiers: Learning from Adverbs in Instructional Videos Hazel Doughty, Ivan Laptev, Walterio Mayol-Cuevas and Dima Damen Conference on Computer Vision and Pattern Recognition (CVPR), 2020. [Webpage] [arXiv] [Dataset and Code] |
| |
The EPIC-KITCHENS Dataset: Collection, Challenges and Baselines Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Sanja Fidler, Antonino Furnari, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, Michael Wray Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2020. [arXiv Preprint] |
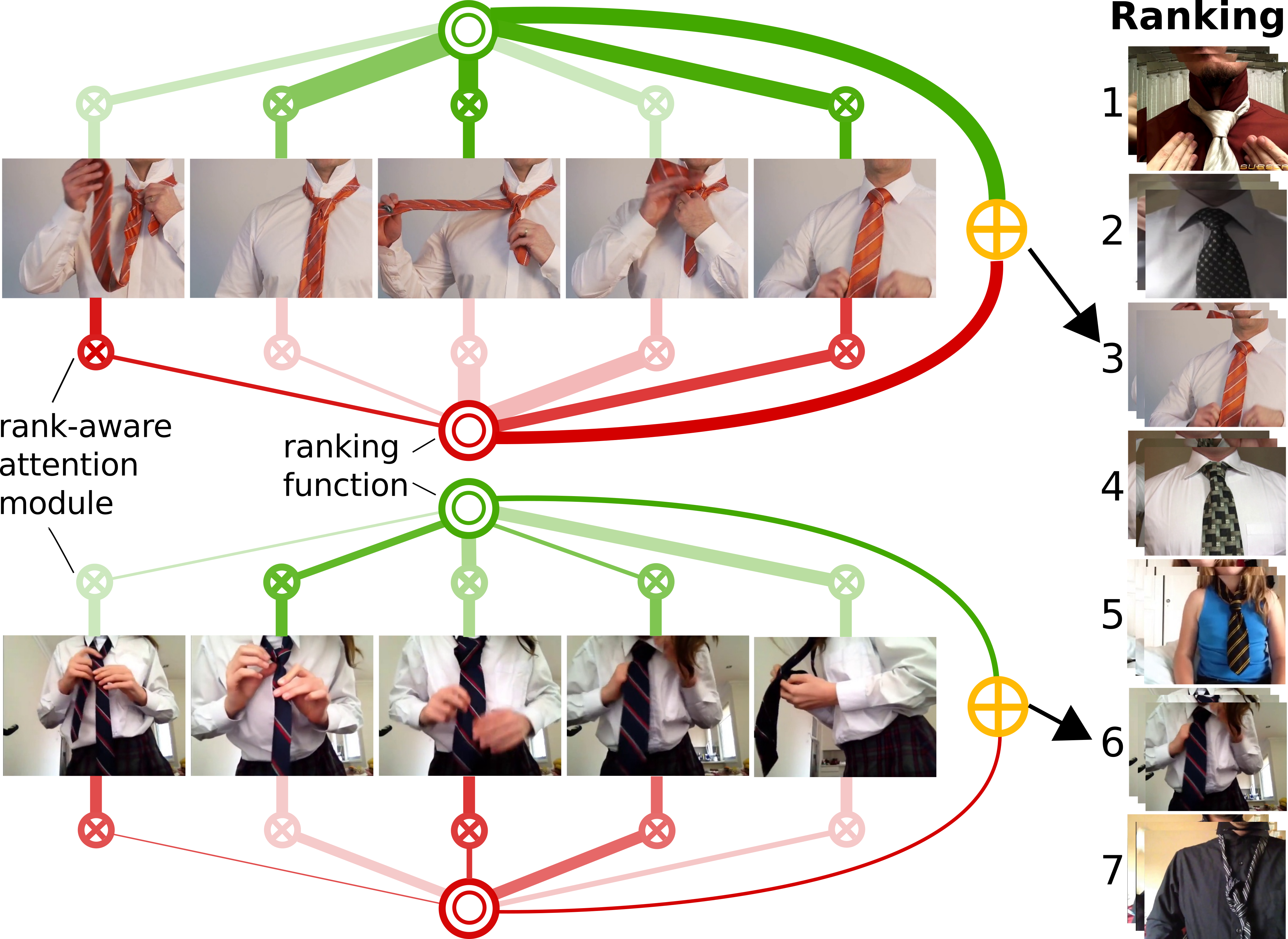 |
The Pros and Cons: Rank-Aware Temporal Attention for Skill Determination in Long Videos Hazel Doughty, Walterio Mayol-Cuevas and Dima Damen Conference on Computer Vision and Pattern Recognition (CVPR), 2019. [Webpage] [arXiv] [Dataset & Code] |
 |
Scaling Egocentric Vision: The EPIC-Kitchens Dataset Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Sanja Fidler, Antonino Furnari, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, Michael Wray European Conference on Computer Vision (ECCV), 2018. (Oral) [arXiv] [Webpage & Dataset] |
 |
Who's Better? Who's Best? Pairwise Deep Ranking for Skill Determination Hazel Doughty, Dima Damen and Walterio Mayol-Cuevas Conference on Computer Vision and Pattern Recognition (CVPR), 2018. (Spotlight) [arXiv] [Bibtex] [Dataset] |
People
- 2024-present - Luc Sträter
- 2024-present - Kaiting Liu
- 2024-present - Omar Emara (PhD with Dima Damen at University of Bristol)
- 2023-2024 Aozhu Chen (Visting PhD student from Renmin University of China)
- 2021-2024 - Yunhua Zhang (PhD with Cees Snoek) now researcher at Genmo AI
- 2021-2023 - Fida Mohammad Thoker (PhD student) now postdoc at KAUST
- 2020-present - Sarah Rastegar (PhD with Cees Snoek)
- 2021-2022 - Piyush Bagad (MS intern) now PhD student at University of Oxford
Grants
 |
NWO High Tech Systems and Materials Co-Applicant of DUAL-mode IMaging for Production and Automated Control Technologies (DUAL-IMPACT) 2025 - Present, €1.25M |
| |
NWO Veni Main Applicant of From What to How: Perceiving Subtle Differences in Videos Oct 2023 - Present, €280K |
Academic Service
Organizer: What is Next in Video Understanding? CVPR 2024 Workshop, Workshop Chair for BMVC 2023, Netherlands Conference on Computer Vision 2022 and 2024, NeurIPS'21 Workshop on Pre-registration in ML, ICCV'21 Workshop on Structured Representations for Video Understanding, WiCV@CVPR2020, EPIC@CVPR2020, EPIC@ECCV2020
Area Chair: ECCV 2026, CVPR 2026, NeurIPS 2025, ICCV 2025, CVPR 2025, NeurIPS 2024, ECCV 2024, ACCV 2024, AAAI 2024, ICCV 2023, WACV 2023
Associate Editor: TPAMI since 2025, CVIU since 2023
Reviewer: CVPR since 2020, ICCV since 2019, ECCV since 2020, TPAMI 2020-2022, IJCV 2021-2022, NeurIPS 2022, ACCV 2020, WACV 2020-2021, AAAI 2020
Outstading Reviewer: CVPR 2024, NeurIPS 2023, CVPR 2023, ECCV 2022, ICCV 2021, CVPR 2021, ECCV 2020, ACCV 2020
Teaching
Computer Vision, 3rd Year Bachelors, Leiden University, 2024-present.
Seminar in Advances of Deep Learning, Masters, Leiden University, 2024-present.
Bachelor Project, 3rd Year Bachelors, Leiden University, 2025-present.
Leren en Beslissen (Learning and Decision Making), 2nd Year Bachelors, University of Amsterdam, 2022.